Learning trajectory tracking under disturbances using a differentiable simulator for drone control
Abstract—Drones are being used more frequently in a variety of industries, including transportation, inspection, and videogra- phy. However, the limited capacity of onboard computing power, constrained by weight and energy consumption, presents a signifi- cant challenge. Therefore, there is a need to enhance the efficiency and accuracy of control systems. This project investigates the potential of learning-based methods for trajectory tracking in the presence of disturbances, such as wind. By using a differentiable simulator for drone control, we have shown that modifying a pretrained model can improve noise rejection capabilities. Furthermore, we introduce an effective wind estimation method. Our findings suggest a substantial enhancement in drone control under adverse conditions, which could lead to more robust and reliable aerial robotics applications.
INTRODUCTION
With the increasing capabilities of hardware and software, drones are becoming more versatile and can be used for a variety of tasks, including transportation, inspection, and videography. To maximize the drone’s potential for its in- tended purpose, it is crucial to design an efficient system that allows for extended operation and optimal movement. This highlights the need for more precise and efficient control systems. Model-Predictive Control (MPC) [4] can be used for trajectory control of a drone, with a trade-off between computational efficiency and high-performance tracking. It is a traditional control method that is commonly employed in drone control systems. However, the use of Reinforcement Learning to compute the control input for trajectory tracking strikes a balance between computational load and precision. This is because the thrust required for the drone can be computed by a single forward pass through the trained policy network. In this work, the training of the drone control is achieved by using an analytic policy gradient solution, which is enabled be using a differentiable simulator of the drone. We build on the work of Wiedemann et al. [1], using their trained policy to extend the network and fine-tune the current model with added wind noise.
SETUP & MODIFICATIONS
A. State, Reference, Action and Preprocessing
The initial state, originally 12-dimensional (comprising po- sition, orientation, velocities and angular velocities) St, is pre- processed to represent velocity in both world and body frames. The orientation is described using the first two columns of the rotation matrix, and for reference, the subsequent τ desired positions relative to the drone’s current position and the next τ desired velocities in the world frame are preprocessed. In all experiments, we set τ = 10.
Additionally, the actions at generated by the policy network exist in a 4-dimensional space. One dimension corresponds to the total thrust (T), and the remaining three dimensions represent the desired body rates (θ ̇des) in the roll, pitch, and yaw axes.

B. Baseline Policy Network Implementation
The baseline policy network employs a neural network for processing the state and the reference to extract time-series features. The neural network generates 10 four-dimensional actions, representing the total thrust (T) and desired body rates (θ ̇des ).
We aim to investigate online adaptability, which involves being adaptive to new and changing environments.
1) Policy Network Architecture Modification: In refining output actions concerning dispersion, an additional input is introduced — a vector that predicts the wind velocity from the current state measurement. We modified the network architecture, as shown in Figure 2.
The neural network processes state, wind vector and ref- erence inputs through an input layer. The yellow part is the modified part of the network. To maintain stable training, the current state and reference state input layers are used from a pre-trained baseline model. The training loop is also extended to include episodes with multiple concurrent updates to exploit the effect of correlated noise, as using one concurrent update per episode does not allow learning the effect of correlated noise.
During the training of the extended model we encountered the issue of vanishing gradients. This might be due to the train- ing data used, as the sampled wind vectors were distributed uniformly between -3 and 3, for each cartesian axis. Due to this input size, the network tanh activation functions might vanish and lead to very slow learning progress. To mitigate this issue, we normalized the new wind input with a simlog function, which is defined as follows:
This led to more stable learning with improved gradients.

C. Particle Filter
We implement a particle filter (PF), a sequential Monte Carlo method, to estimate the wind vector that affects the dynamics of the drone. This estimation is critical to provide the network with accurate wind vector data, along with the drone’s current measurable states and a reference. The network then synthesizes this information to determine the drone’s subsequent actions.
a) Initialization: The PF begins by initializing a set of particles that represent hypotheses about the drone’s state, including an assumed wind vector. Each particle is initialized to the current state of the drone, augmented with a wind vector sampled from a Gaussian distribution. In the absence of direct wind measurements, the variance assigned to the wind vector samples is significantly higher than that assigned to the drone states, reflecting the greater uncertainty associated with wind conditions.
b) Prediction: In the prediction phase, we simulate the future state of each particle using the physical model of the drone, taking into account the acceleration caused by the wind. This step moves each particle according to the system dynamics influenced by the assumed wind vector.
c) Update: During the update phase, we refine our particle hypotheses based on new measurements of the drone’s state. We compute a likelihood for each particle by comparing its predicted state to its actual measured state, using the discrepancy as the basis for weighting the particle’s likelihood. This approach allows us to assess the plausibility of each particle’s assumed wind vector.
d) Resampling: With the particles weighted by their likelihood, we proceed to resample, prioritizing particles that more closely match the observed data. This step concentrates our particle set around the most likely states, effectively focusing our hypotheses on high likelihood regions.
e) Estimate: Finally, we estimate the wind vector by aggregating the resampled particles. This process provides an approximation of the unobserved wind vector, using the collective inference of our particle set to infer the most likely environmental conditions affecting the drone.
FIRST RESULTS
A. Testing the Baseline Model with Diverse Noise Forces
Our developed testing framework was employed to rigor- ously evaluate the baseline policy network model. We tested the baseline with a constant noise, sampled uniformly for every component of the wind vector in the absolute Cartesian coordinate system between -3 and 3.
To quantify the impact of each noise type, we measured the average divergence as our key metric. The results are summarized in Table I, where the numbers are illustrated below:

These numerical results show that the baseline model ex- periences the least divergence and achieves the highest score under normal conditions (no noise). As the noise magnitude increases, we can see that the average divergence of the model rises to 1.18, indicating its effectiveness in challenging the robustness of the model. The corresponding decrease in score is consistent with the increased difficulty posed by various noise forces.
B. Training & Testing the Modified Model with Diverse Noise Forces
In Table II we see that the modified model was able to improve the average divergence compared to the baseline model. In total, we see an improvement of 27.6 %. In Figure 3 we can see a direct comparison between the baseline model trajectory and the modified network trajectory, where we can see a small decrease in the trajectory’s divergence from the reference.

C. Particle Filter Results
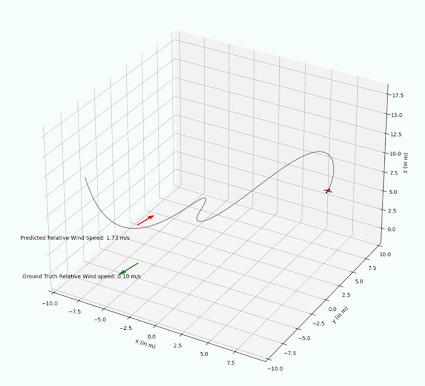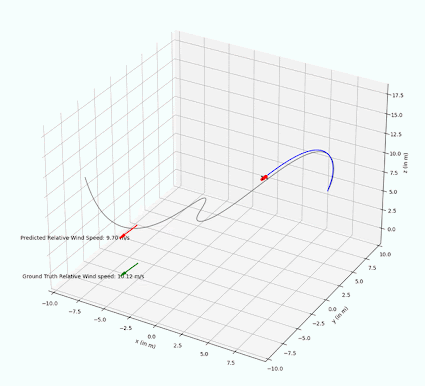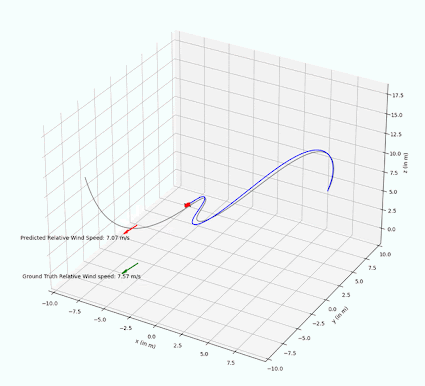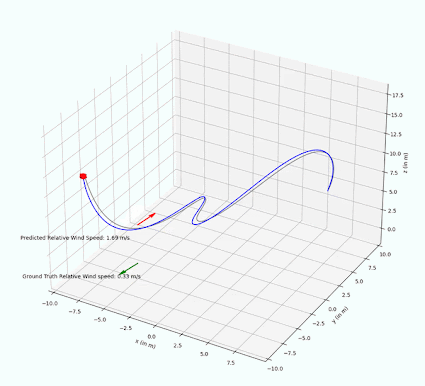
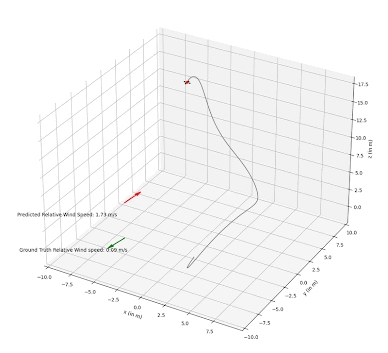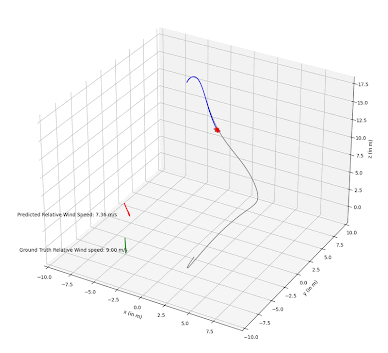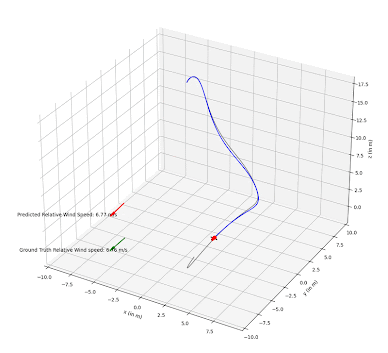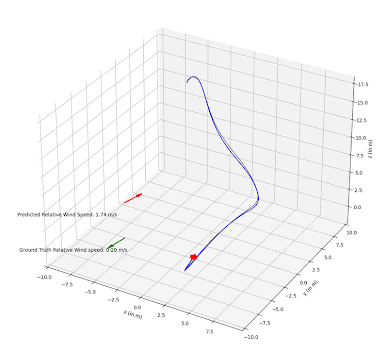
The implemented PF is able to successfully estimate wind vectors by sequentially sampling the drone and wind state with a random noise. In experiments, we are able to observe that the estimated relative wind vector follows the ground truth vector with only a small delay. In 4 we can visually see that the red arrow representing the estimated wind speed is pointing in the same direction as the ground truth wind vector.

The PF performance has only been qualitatively tested with constant wind noise, but leads to the assumption that it is technically possible to track changing wind vectors, provided the rate of change is not too fast.
Observations and Analysis
a) Average Divergence: The modified model shows a reduced average divergence compared to the baseline in noisy conditions. In particular, the introduction of the normalized wind vectors through the simlog function allowed us to train the model well beyond the previous performance of the modified model. When evaluating the performance on 1000 trajectory examples with sampled uniform wind in each episode (i.e. different directions and magnitudes), we can observe that the model performance has improved compared to the baseline, although not as much as expected.
Considerations for Future Modifications: The observed performance differences suggest several possibilities for im- provement:
1) Model adaption: Instead of processing the immedi- ate state and the estimated wind vector alongside the reference, incorporating historical data (past states and actions) could enrich the model’s context, potentially obviating the need for particle filter estimation. This approach could reduce computational requirements and improve prediction accuracy by adding a temporal di- mension to the analysis.
2) Simulation To Real World: Another next step would be to conduct experiments on a real system to find out if the controller is able to work efficiently not only with wind noise, but also with a mechanical system where not all properties can be simulated.
CONCLUSION
This report investigates the effects of wind perturbations on a reinforcement learning model designed for trajectory tracking, along with strategies for model improvement. We evaluated the trajectory tracking performance of both the baseline and modified models under conditions of randomly sampled wind perturbations. In addition, we demonstrated the ability to estimate unobservable wind vectors through the implementation of a particle filter, thereby improving the model’s resilience to environmental variables.
REFERENCES
-
[1] Wiedemann, Nina, et al. ”Training efficient controllers via analytic policy gradient.” 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023.
-
[2] C. D. Freeman, E. Frey, A. Raichuk, S. Girgin, I. Mordatch, and O. Bachem, “Brax-a differentiable physics engine for large scale rigid body simulation,” in Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), 2021
-
[3] Y. Song, M. Steinweg, E. Kaufmann, and D. Scaramuzza, “Autonomous drone racing with deep reinforcement learning,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 1205–1212.
-
[4] S. J. Qin and T. A. Badgwell, ”An overview of industrial model predictive control technology,” in AIChE Symposium Series, vol. 93, no. 316, pp. 232–256, 1997, New York, NY: American Institute of Chemical Engineers, 1971-c2002.
Comments
Post a Comment